Fine-tuning Flux.1-dev LoRA on yourself

Impressed by the image-generation capabilities of Flux, I decided to dive in and experience it for myself. This blog is a personal guide to fine-tuning Flux 1.1-dev LoRA to create high-quality, lifelike images of myself—all without the hassle of taking photos. As someone who prefers working with computers over cameras and exploring AI for fun rather than research, this experiment lets me sidestep my camera shyness while enjoying the cutting-edge possibilities of AI creativity.
Here are some images of myself generated by Flux.1-dev LoRA



Prerequisites
This tutorial is not the only way to fine-tune Flux.1-dev LoRA, you can train Flux.1-dev LoRA on Google colab, or using online services. But because this tutorial is using local GPU, you need to prepare the following to run it smoothly:
- You are a developer
- OS: Ubuntu Linux
- Nvidia GPU, at least 12GB VRAM
- Python 3.10 or 3.11
I did not write the code for this training. Instead, I used SimpleTuner to fine-tune Flux.1-dev LoRA. You can refer directly to the SimpleTuner documentation for instructions on fine-tuning Flux.1-dev LoRA.
Environment Setup
$ git clone --branch=release https://github.com/bghira/SimpleTuner.git
$ cd SimpleTuner
$ python -m venv .venv
$ source .venv/bin/activate
$ pip install -U poetry pip
$ poetry config virtualenvs.create false
$ poetry install
Dataset preparation
The dataset
To create your own Flux model, you need to prepare some of your images, just 5 images is enough, but 20 images is better. The quality of the image contributes greatly to the effectiveness of the model, consider the following factors:
- WebP, JPG, and PNG formats are all supported
- Use 1024x1024 or higher resolution if possible.
- The photo shows a clear face, without accessories, eg glasses.
- Photos share different angles of the face.
- The photo collection should be diverse (e.g. angles, outfits, ...)
- Photos should be taken within the last 6 months.
 Credits: Replicate
Credits: Replicate
The trigger word
When fine-tuning Flux with your images, it’s essential to choose a unique trigger word that represents your face. This trigger word will act as a key for generating images of your likeness. Ideally, the trigger word should be distinct and specific to your face, avoiding any overlap with common objects or concepts to ensure accurate results.
Here are the tips to choose a good trigger word:
- The trigger word should not be a word found in any language dictionary. For example, 'face' or 'flower' is not a good trigger word.
- Make it short, because it will take some space in the prompt.
- Example: hieunv3, behitek are good trigger words.
Reason: The words in dictionary can be easily recognized by the model, and the model will not be able to generate images of your likeness.
Generate captions
For better quality, you should generate a caption for each image. Here, I will use the Microsoft Florence 2 model to generate captions for the images. You can also use ChatGPT, llava or llama3.2 to generate captions.
After captions are generated, add your trigger word to the beginning of the captions. For example (using behitek as the trigger word):
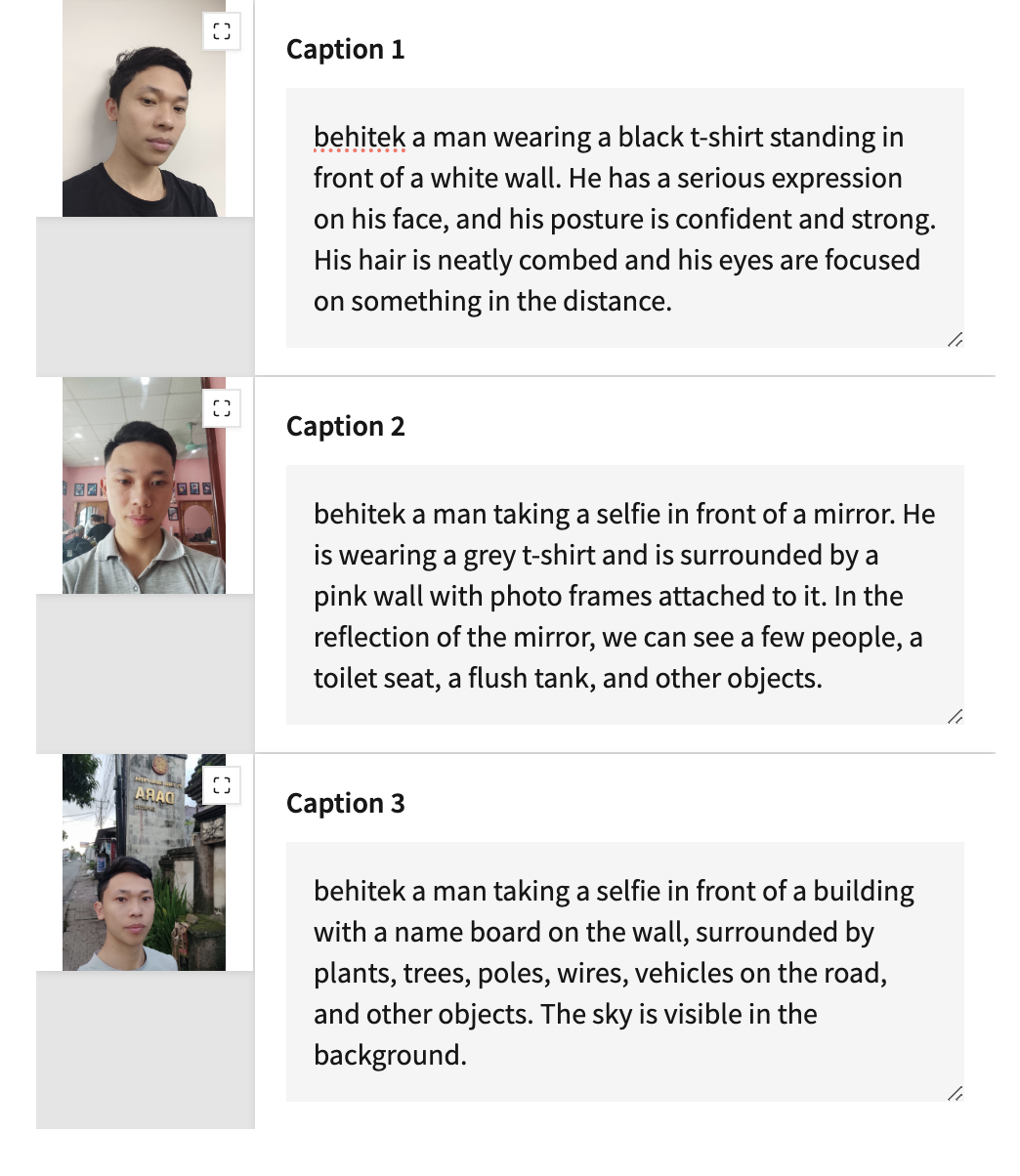
Do organize your images and captions in a folder, and put them in a folder with structure like this:
$ tree .
├── 1000003258.jpg
├── 1000003258.txt
├── 1000003259.jpg
├── 1000003259.txt
├── 1000003262.jpg
├── 1000003262.txt
├── 1000003263.jpg
├── 1000003263.txt
├── 1000003264.jpg
├── 1000003264.txt
├── 1000003265.jpg
├── 1000003265.txt
├── IMG_20220326_135114.jpg
├── IMG_20220326_135114.txt
├── IMG_20220706_184917.jpg
├── IMG_20220706_184917.txt
├── IMG_20230512_150235.jpg
├── IMG_20230512_150235.txt
├── IMG_20230719_065425.jpg
├── IMG_20230719_065425.txt
Where *.JPG is the image, and the same file name with extension *.TXT contains the caption of the image. I will assume this dataset directory is located in /path/to/datasets/behitek-lora.
Training configuration
Go back to SimpleTuner, you can find the configuration sample in the config folder.
Create your own config
cd config/
cp config.json.example config.json
cp lycoris_config.json.example lycoris_config.json
cp user_prompt_library.json.example user_prompt_library.json
cp multidatabackend.json.example dataset.behitek.json
I will provide you a sample config for you to fine-tune Flux.1-dev LoRA, with trigger word behitek.
The config.json
This is the config.json file, update the following key:
--validation_prompt, enter your prompt with trigger word.--data_backend_config,--output_dir,--lycoris_config, and--user_prompt_library, make sure they are correct.
{
"--resume_from_checkpoint": "latest",
"--data_backend_config": "config/dataset.behitek.json",
"--aspect_bucket_rounding": 2,
"--seed": 42,
"--minimum_image_size": 0,
"--output_dir": "output/behitek-lycoris-v0.1",
"--lora_type": "lycoris",
"--lycoris_config": "config/lycoris_config.json",
"--max_train_steps": 10000,
"--num_train_epochs": 0,
"--checkpointing_steps": 1000,
"--checkpoints_total_limit": 5,
"--hub_model_id": "simpletuner-lora",
"--push_to_hub": "false",
"--push_checkpoints_to_hub": "false",
"--tracker_project_name": "lora-training",
"--tracker_run_name": "simpletuner-lora",
"--report_to": "tensorboard",
"--model_type": "lora",
"--pretrained_model_name_or_path": "black-forest-labs/FLUX.1-dev",
"--model_family": "flux",
"--train_batch_size": 1,
"--gradient_checkpointing": "true",
"--caption_dropout_probability": 0.1,
"--resolution_type": "pixel_area",
"--resolution": 1024,
"--validation_seed": 42,
"--validation_steps": 1000,
"--validation_resolution": "1024x1024",
"--validation_guidance": 3.0,
"--validation_guidance_rescale": "0.0",
"--validation_num_inference_steps": "20",
"--validation_prompt": "behitek a man sitting on a chair wearing a white shirt, focused on the book he is holding in his hand. On the table in front of him is an object, and behind him are a few people, trees, and a blue sky",
"--mixed_precision": "bf16",
"--optimizer": "adamw_bf16",
"--learning_rate": "1e-4",
"--lr_scheduler": "polynomial",
"--lr_warmup_steps": 100,
"--validation_torch_compile": "false",
"--disable_benchmark": "false",
"--base_model_precision": "int8-quanto",
"--text_encoder_1_precision": "no_change",
"--text_encoder_2_precision": "no_change",
"--lora_rank": 16,
"--max_grad_norm": 1.0,
"--base_model_default_dtype": "bf16",
"--user_prompt_library": "config/user_prompt_library.json"
}
Notes:
- I use
base_model_precision=int8-quantofor VRAM saving. - Every
validation_steps, the model will generate validation images, and save them to thevalidation_imagesfolder inside theoutput_dir. train_batch_size=1is a recommended value (by SimpleTuner) for small dataset.
The user_prompt_library.json
The user_prompt_library.json file is a list of prompts, you can add prompts here. During the model validation, it will generate images based on these prompts. Example:
{
"behitek_1": "behitek A 30-year-old man with a rugged yet stylish look, dressed in a beige explorer jacket with cargo pants, standing on the edge of a cliff at sunset, overlooking a vast canyon. His expression is a mix of awe and determination. The scene is rich with glowing orange and red hues, with wind tousling his hair.",
"behitek_2": "behitek A 30-year-old man with a sharp jawline, wearing a sleek black turtleneck and tailored gray trousers, walking confidently down a bustling city street. Neon lights from billboards reflect on the wet pavement, creating a vibrant, futuristic cityscape."
}
The dataset.behitek.json
The dataset.behitek.json file:
[
{
"id": "behitek-subject",
"type": "local",
"crop": true,
"crop_style": "center",
"crop_aspect": "square",
"resolution": 1024,
"minimum_image_size": 1024,
"maximum_image_size": 1024,
"target_downsample_size": 1024,
"resolution_type": "pixel_area",
"cache_dir_vae": "cache/vae/flux/behitek-subject",
"instance_data_dir": "/path/to/datasets/behitek-lora",
"caption_strategy": "textfile",
"instance_prompt": "behitek",
"metadata_backend": "discovery",
"is_regularisation_data": false,
"repeats": 1000
},
{
"id": "behitek-subject-512",
"type": "local",
"crop": true,
"crop_style": "center",
"crop_aspect": "square",
"resolution": 512,
"minimum_image_size": 512,
"maximum_image_size": 512,
"target_downsample_size": 512,
"resolution_type": "pixel_area",
"cache_dir_vae": "cache/vae/flux/behitek-subject-512",
"instance_data_dir": "/path/to/datasets/behitek-lora",
"caption_strategy": "textfile",
"instance_prompt": "behitek",
"metadata_backend": "discovery",
"is_regularisation_data": false,
"repeats": 1000
},
{
"id": "text-embeds",
"type": "local",
"dataset_type": "text_embeds",
"default": true,
"cache_dir": "cache/text/flux",
"disabled": false,
"write_batch_size": 128
}
]
Notes:
- Make sure to correct the
instance_data_dirto your dataset directory. - If your image dimension is smaller than 1024x1024, you will got the error:
No images were discovered by the bucket .... - There is several
caption_strategy, buttextfileis the right setting. repeatsis the number of times to repeat the same image, 1000 is a good number.
The lycoris_config.json
For the lycoris_config.json file, leave it as it is, the default setting is fine.
Training
Still in the root directory of SimpleTuner, run the following command:
$ tmux new -s train # create a new tmux session
$ source ./venv/bin/activate
./train.sh
During training, the model will generate images based on the prompts in the user_prompt_library.json and validation_prompt in the config file, these images is save in your output_dir.
Training Experience
- If your dataset consists only of faces (neck and head) with a clean background, you don't need to generate captions. Simply use
caption_strategy: "instanceprompt", where theinstancepromptserves as the trigger word. In this case, 2000 training steps are sufficient. - For diverse data (e.g., different outfits, backgrounds, or even the same person in varied settings), generating captions is recommended. With more diverse data, training for more steps is beneficial. For example, 10,000 steps is a good benchmark.
- If you're unsure when the model has converged, check the loss curve in TensorBoard and save additional checkpoints for safety.
Inference
Once the model is trained, you can use the below Python script (not a clean code) to generate images:
import torch
from diffusers import DiffusionPipeline
from lycoris import create_lycoris_from_weights
import os
model_id = 'black-forest-labs/FLUX.1-dev'
adapter_file_path = "/path/to/output_dir/pytorch_lora_weights.safetensors"
pipeline = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.bfloat16) # loading directly in bf16
lora_scale = 1.0
wrapper, _ = create_lycoris_from_weights(lora_scale, adapter_file_path, pipeline.transformer)
wrapper.merge_to()
## Optional: quantise the model to save on vram.
## Note: The model was quantised during training, and so it is recommended to do the same during inference time.
from optimum.quanto import quantize, freeze, qint8
quantize(pipeline.transformer, weights=qint8)
freeze(pipeline.transformer)
output_dir = os.path.join("output", "behitek-hitech")
os.makedirs(output_dir, exist_ok=True)
prompts = [
"behitek A 30-year-old man with a rugged yet stylish look, dressed in a beige explorer jacket with cargo pants, standing on the edge of a cliff at sunset, overlooking a vast canyon. His expression is a mix of awe and determination. The scene is rich with glowing orange and red hues, with wind tousling his hair.",
"behitek A 30-year-old man with a sharp jawline, wearing a sleek black turtleneck and tailored gray trousers, walking confidently down a bustling city street. Neon lights from billboards reflect on the wet pavement, creating a vibrant, futuristic cityscape.",
"behitek A young man, 30 years old, sitting in a high-tech office filled with holographic screens and futuristic gadgets. He’s wearing a casual blazer over a graphic T-shirt and glasses with a subtle glow, symbolizing augmented reality.",
"behitek A 30-year-old warrior with a chiseled physique, clad in intricate silver armor with glowing blue runes. He holds a massive sword that emits a faint magical aura. He stands on a battlefield surrounded by mythical creatures under a dark, stormy sky.",
"behitek A 30-year-old man with a cheerful demeanor, dressed in outdoor gear, standing beside a sparkling mountain lake. A camera hangs from his neck, and his backpack is packed with supplies. The serene landscape features towering pine trees and a snow-capped peak in the background.",
"behitek A young man, 30 years old, styled in 1980s adventure fashion—khaki shorts, a buttoned shirt, and a leather satchel. He is mid-action, leaping over a crumbling stone bridge in an ancient jungle temple, vines and artifacts all around.",
"behitek A 30-year-old man in a contemporary interpretation of samurai attire, blending traditional armor with urban streetwear. He holds a katana and stands in an empty urban alley lit by paper lanterns, exuding a calm yet powerful presence.",
"behitek A young man in his 30s, dressed in a futuristic spacesuit with a sleek, glowing helmet. He floats in the vastness of space, with a swirling galaxy visible in the background. The stars and nebulae create a stunning, ethereal glow.",
"behitek A 30-year-old man in Renaissance clothing—ruffled shirt and velvet coat—standing in an ornate studio. He is surrounded by canvases, sculptures, and paints. His face reflects deep concentration as he works on a masterpiece.",
"behitek A young man, 30 years old, sitting in a grand library filled with towering shelves of ancient books. He’s wearing a long coat with mystical symbols embroidered in gold, surrounded by floating magical texts and glowing orbs."
]
import random
for idx, prompt in enumerate(prompts):
for i in range(30):
print(f"Generating image {i}")
seed = random.randint(0, 1000000000)
pipeline.to('cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu') # the pipeline is already in its target precision level
image = pipeline(
prompt=prompt,
num_inference_steps=20,
generator=torch.Generator(device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu').manual_seed(seed),
width=1024,
height=1024,
guidance_scale=3.0,
).images[0]
image.save(os.path.join(output_dir, f"{idx}_{seed}.png"), format="PNG")
With the same prompt, try changing the seed to get different results. In the above bad code, I do generate 30 images for each prompt. From many generated images, you can select some good ones.
That's it! You have now created a Flux LoRa model.